O std::accumulate é um algoritmo de operação numérica, da mesma forma que std::iota explorado anteriormente (http://simplycpp.com/2015/11/06/mestre-iota/), reside no header <numeric> da STL: http://www.cplusplus.com/reference/numeric/accumulate/.
Seu objetivo, até mesmo porque o nome desta função dá uma dica, é acumular elementos que pertencem a um range fornecido por um par de iterators (usualmente begin e end para uma sequência completa). O std::accumulate também possui um valor inicial para o acumulador que é fornecido como terceiro parâmetro desta função.
Supondo um array de tamanho 10 e já inicializado como container de referência para os exemplos a seguir:
https://gist.github.com/fabiogaluppo/3091dbf3ecf3b4061be0
A utilização padrão do std::accumulate com um container qualquer (assim como o indicado acima) é da seguinte forma:
https://gist.github.com/fabiogaluppo/8e8c4c0cbd3640c5eaa4
Onde temos como retorno a soma de todos os elementos do container. Com um container como o array em mãos, logo é possível saber seu tamanho através do membro do tipo função size. Assim podemos, por exemplo, extrair a média de um jeito muito simples:
https://gist.github.com/fabiogaluppo/2bd1badab7fb81b37cbc
Perceba que o valor inicial na chamada anterior retornará um tipo double, em função do valor inicial fornecido ser deste tipo. Então é fácil concluir, tanto pela assinatura de std::accumulate quanto pelo retorno do exemplo anterior, que o tipo inicial e o tipo de retorno serão os mesmos e que o valor do iterator quando for derefenciado deverá ser compatível ou convertível para este tipo.
Nos posts passados, mostramos como é possível ter iterator com predicado e alterar o comportamento do operator++ do tipo fornecido para o std::iota. Podemos juntar estas duas técnicas e fazer o mesmo para o tipo inicial fornecido como terceiro parâmetro da função, como no caso a seguir demonstrado em accumulator_with_predicate. Aqui vai o consumo (note que está sendo usado um intervalo/range parcial do container, e este será filtrado com orientação do predicado indicado):
https://gist.github.com/fabiogaluppo/74e72907ac42b9c5fca1
E o tipo que oferece um novo significado para o operator+ e é convertível para o tipo T compatível com a variável que recebe o retorno da função:
https://gist.github.com/fabiogaluppo/c128606504709b1c7566
Caso ache o algoritmo numérico std::accumulate verboso para apenas somar elementos (de uma parte) do container, sugiro a criação de uma função especialista, como o par de funções sum implementadas em termos de std::accumulate:
https://gist.github.com/fabiogaluppo/9ba7c3fe101ab0beeb0b
Onde o consumo se torna simplificado e extremamente declarativo:
https://gist.github.com/fabiogaluppo/0d9dafde1c5acb6867c3
Outro conceito relacionado com std::accumulate é o fold do estilo de programação funcional com higher-order functions. O std::accumulate (assim como outras funções da biblioteca padrão do C++) é uma higher-order function, que tem um functor ou objeto do tipo função (ou um lambda) como quarto parâmetro a ser informado. Neste caso, é possível mudar o comportamento padrão que é a soma (fornecido pela função std::plus) por outra função com operação binária, como por exemplo uma multiplicação. Suponha que seu objetivo é criar uma função fold no estilo STL:
https://gist.github.com/fabiogaluppo/21970867753efa1c2346
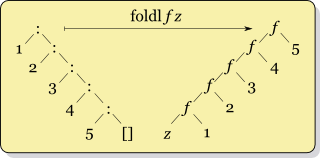
Acima temos a implementação de um fold left, onde a expansão da aplicação consecutiva da função f ocorre pela esquerda, algo interpretado na forma: ...f(f(f(f(f(acc, 1),2),3),4),5)..., se usarmos um reverse iterator teremos um fold right que pode ser interpretado na forma: ...f(f(f(f(f(acc, 5),4),3),2),1)..., as duas figuras a seguir, retiradas da página do Fold na Haskell.org, dá uma noção visual do fold left (foldl) e fold right (foldr):

No entanto, não precisamos desta função fold, pois o próprio std::accumulate é o fold! E tudo que é feito com fold é possível reproduzir com std::accumulate e vice-versa.
https://gist.github.com/fabiogaluppo/ef73a0cd841377b28f78
Dentre as coisas interessantes com std::accumulate (ou fold), conseguimos calcular um hash simples para uma string da seguinte maneira:
https://gist.github.com/fabiogaluppo/4dca638ca6c92683bc2a
Vale lembrar que executar um fold left ou um fold right (std::accumulate com o par de iteradores begin/end e std::accumulate com o par de iteradores rbegin/rend, respectivamente) não garantirá uma equabilidade, pois isto dependerá da operação binária e seu tipo possuir a propriedade comutativa. Por padrão a adição de tipos integrais (short, int, long) e tipos reais (float e double) possuem a propriedade comutativa da adição e da multiplicação:
https://gist.github.com/fabiogaluppo/de025a6721474e16e99e
Porém, a concatenação de strings não possui esta propriedade como podemos ver a seguir:
https://gist.github.com/fabiogaluppo/6ca06c10f47f2f07b62f
A operação fold possui como sua dualidade a operação unfold. Note que fold (ou std::accumulate) retorna um valor combinado, uma espécie de monólito. Imagine que você queira a partir deste bloco obter toda a sequência que o originou. Este é um trabalho para unfold, como segue no exemplo com a acumulação da progressão aritmética gerada:
https://gist.github.com/fabiogaluppo/3c3f0bcc5ba2697763fe
https://gist.github.com/fabiogaluppo/8a92d515241d0edb6b9a
Como demonstrado neste post, o std::accumulate, apesar de ter um propósito bem específico – acumular ou fazer agregação, é uma função bem versátil. Ela também é conhecida popularmente com outros nomes além de fold, são eles: reduce ou aggregate.
Adendo sobre comutatividade e tipos com ponto flutuante (float ou double):
https://gist.github.com/fabiogaluppo/6e8a7464fab8c1cdc515
Fonte:
https://github.com/SimplyCpp/examples/blob/master/understanding_accumulate_program.cpp
Seu objetivo, até mesmo porque o nome desta função dá uma dica, é acumular elementos que pertencem a um range fornecido por um par de iterators (usualmente begin e end para uma sequência completa). O std::accumulate também possui um valor inicial para o acumulador que é fornecido como terceiro parâmetro desta função.
Supondo um array de tamanho 10 e já inicializado como container de referência para os exemplos a seguir:
https://gist.github.com/fabiogaluppo/3091dbf3ecf3b4061be0
A utilização padrão do std::accumulate com um container qualquer (assim como o indicado acima) é da seguinte forma:
https://gist.github.com/fabiogaluppo/8e8c4c0cbd3640c5eaa4
Onde temos como retorno a soma de todos os elementos do container. Com um container como o array em mãos, logo é possível saber seu tamanho através do membro do tipo função size. Assim podemos, por exemplo, extrair a média de um jeito muito simples:
https://gist.github.com/fabiogaluppo/2bd1badab7fb81b37cbc
Perceba que o valor inicial na chamada anterior retornará um tipo double, em função do valor inicial fornecido ser deste tipo. Então é fácil concluir, tanto pela assinatura de std::accumulate quanto pelo retorno do exemplo anterior, que o tipo inicial e o tipo de retorno serão os mesmos e que o valor do iterator quando for derefenciado deverá ser compatível ou convertível para este tipo.
Nos posts passados, mostramos como é possível ter iterator com predicado e alterar o comportamento do operator++ do tipo fornecido para o std::iota. Podemos juntar estas duas técnicas e fazer o mesmo para o tipo inicial fornecido como terceiro parâmetro da função, como no caso a seguir demonstrado em accumulator_with_predicate. Aqui vai o consumo (note que está sendo usado um intervalo/range parcial do container, e este será filtrado com orientação do predicado indicado):
https://gist.github.com/fabiogaluppo/74e72907ac42b9c5fca1
E o tipo que oferece um novo significado para o operator+ e é convertível para o tipo T compatível com a variável que recebe o retorno da função:
https://gist.github.com/fabiogaluppo/c128606504709b1c7566
Caso ache o algoritmo numérico std::accumulate verboso para apenas somar elementos (de uma parte) do container, sugiro a criação de uma função especialista, como o par de funções sum implementadas em termos de std::accumulate:
https://gist.github.com/fabiogaluppo/9ba7c3fe101ab0beeb0b
Onde o consumo se torna simplificado e extremamente declarativo:
https://gist.github.com/fabiogaluppo/0d9dafde1c5acb6867c3
Outro conceito relacionado com std::accumulate é o fold do estilo de programação funcional com higher-order functions. O std::accumulate (assim como outras funções da biblioteca padrão do C++) é uma higher-order function, que tem um functor ou objeto do tipo função (ou um lambda) como quarto parâmetro a ser informado. Neste caso, é possível mudar o comportamento padrão que é a soma (fornecido pela função std::plus) por outra função com operação binária, como por exemplo uma multiplicação. Suponha que seu objetivo é criar uma função fold no estilo STL:
https://gist.github.com/fabiogaluppo/21970867753efa1c2346
Acima temos a implementação de um fold left, onde a expansão da aplicação consecutiva da função f ocorre pela esquerda, algo interpretado na forma: ...f(f(f(f(f(acc, 1),2),3),4),5)..., se usarmos um reverse iterator teremos um fold right que pode ser interpretado na forma: ...f(f(f(f(f(acc, 5),4),3),2),1)..., as duas figuras a seguir, retiradas da página do Fold na Haskell.org, dá uma noção visual do fold left (foldl) e fold right (foldr):
No entanto, não precisamos desta função fold, pois o próprio std::accumulate é o fold! E tudo que é feito com fold é possível reproduzir com std::accumulate e vice-versa.
https://gist.github.com/fabiogaluppo/ef73a0cd841377b28f78
Dentre as coisas interessantes com std::accumulate (ou fold), conseguimos calcular um hash simples para uma string da seguinte maneira:
https://gist.github.com/fabiogaluppo/4dca638ca6c92683bc2a
Vale lembrar que executar um fold left ou um fold right (std::accumulate com o par de iteradores begin/end e std::accumulate com o par de iteradores rbegin/rend, respectivamente) não garantirá uma equabilidade, pois isto dependerá da operação binária e seu tipo possuir a propriedade comutativa. Por padrão a adição de tipos integrais (short, int, long) e tipos reais (float e double) possuem a propriedade comutativa da adição e da multiplicação:
https://gist.github.com/fabiogaluppo/de025a6721474e16e99e
Porém, a concatenação de strings não possui esta propriedade como podemos ver a seguir:
https://gist.github.com/fabiogaluppo/6ca06c10f47f2f07b62f
A operação fold possui como sua dualidade a operação unfold. Note que fold (ou std::accumulate) retorna um valor combinado, uma espécie de monólito. Imagine que você queira a partir deste bloco obter toda a sequência que o originou. Este é um trabalho para unfold, como segue no exemplo com a acumulação da progressão aritmética gerada:
https://gist.github.com/fabiogaluppo/3c3f0bcc5ba2697763fe
https://gist.github.com/fabiogaluppo/8a92d515241d0edb6b9a
Como demonstrado neste post, o std::accumulate, apesar de ter um propósito bem específico – acumular ou fazer agregação, é uma função bem versátil. Ela também é conhecida popularmente com outros nomes além de fold, são eles: reduce ou aggregate.
Adendo sobre comutatividade e tipos com ponto flutuante (float ou double):
https://gist.github.com/fabiogaluppo/6e8a7464fab8c1cdc515
Fonte:
https://github.com/SimplyCpp/examples/blob/master/understanding_accumulate_program.cpp
Hi! Post bacana, mas você disse que adição em float é comutativa e isso não procede né?
ResponderExcluirOlá Ricardo,
ResponderExcluirObrigado pela observação muito pertinente!
Matematicamente, os números reais são um grupo abeliano (ou grupo comutativo) sob a adição, e os números reais não incluindo o zero são um grupo abeliano sob a multiplicação. Logo, a comutatividade estará ok.
Computacionalmente, para tipos reais ou de ponto flutuante (float ou double) as operações poderão sofrer uma taxa de erro, nestes casos a comparação usando um "epsilon" se torna necessária. Uma abordagem completa sobre este assunto pode ser encontrada aqui: https://randomascii.wordpress.com/2012/02/25/comparing-floating-point-numbers-2012-edition/
Fiz um adendo no post com alguns exemplos.
Grande abraço,